Happy Fractal
Repository: https://github.com/tcsullivan/happy-fractal
I was first exposed to fractals in elementary school. The tech teacher at the time was familiar with open-source software, installing programs like TuxType and TuxPaint on the school's computers. This collection also included XaoS, a fun, easy-to-use program that lets you spend hours zooming around many different fractals.
Fractal generation and exploration makes for a great programming challenge, requiring smooth graphical performance and fast, precise calculations. I first got a taste of the code through a simple Mandelbrot viewer that I contributed to on GitHub. Following this, I was inspired to give the challenge my own go.
This also gave me a chance to study OpenCL, which allows for fast parallel computing on GPUs. The speed difference between this and CPU-bound calculations is undeniable, and can be tested by changing a compile-time flag.
double is a very precise type, but its limits can be found after zooming for a while. The image will begin to stretch and distort, before falling apart into a mess of colored bars:

XaoS does not suffer like this, and can actually zoom in much further. In an effort to match these capabilities, I began implementing a fixed-point alternative to double.
The largest type I could send to the GPU through OpenCL is a uint64_t; however, this is the same bit-size as double, so a pair of uint64_ts are needed to achieve superior precision. This lead me to fixed-point arithmetic and a library called r128, which uses two uint64_ts to provide Q64.64 fixed-point numbers.
However, double already uses 52 bits for its mantissa; a jump to 64 bits is not that significant. By modifying r128, I was able to give more bits to the fractional part of the number. Since the Mandelbrot set is also contained to just a small region around the origin (0, 0), the fixed-point format could be changed to Q4.124 to provide twice as many fractional bits while still rendering the entire fractal.
floating-point vs. fixed-point
Below is the Mandelbrot set generated with double (left) and Q4.124 fixed-point (right). There are some major differences in the larger outlines of the fractal, but the fixed-point version shows additional details further inside.
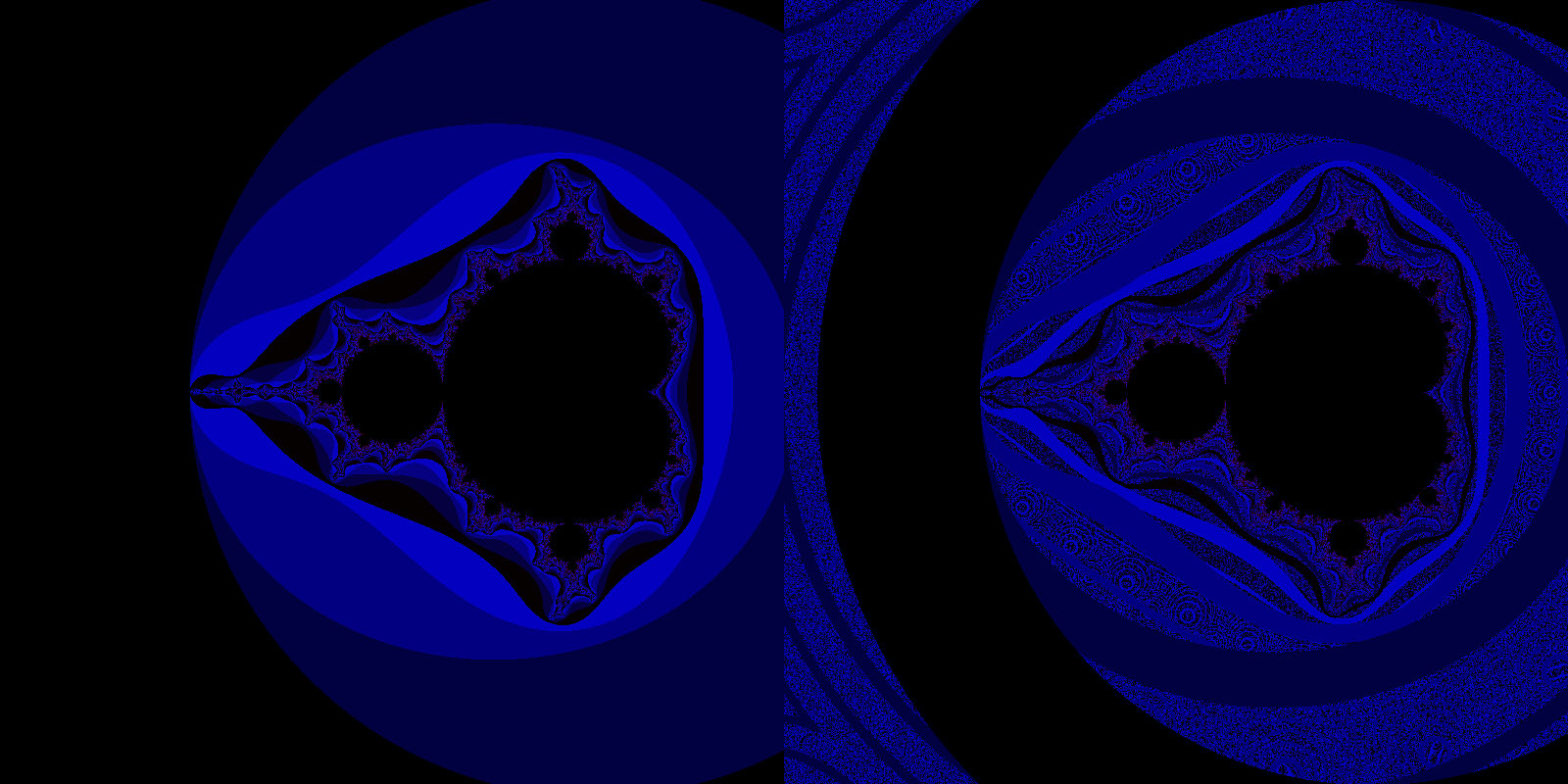
Returning to the point where the floating-point implementation fell apart, the fixed-point version is able to zoom much closer to the center of the image. It even reaches a change from pink to blue that is barely visible in the original shot:
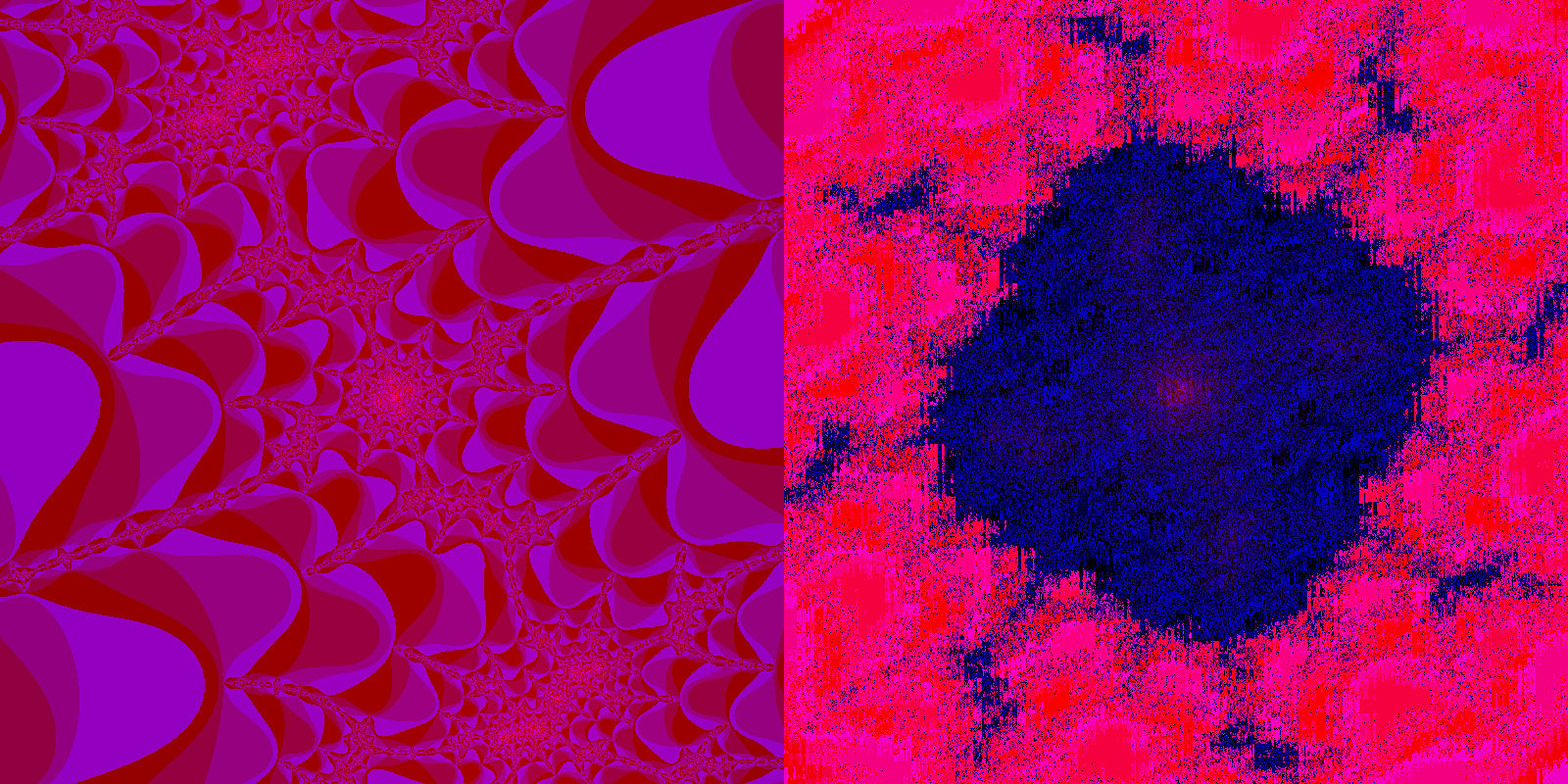
fixed-point vs. XaoS
The fixed-point implementation puts up a decent fight against XaoS. Unlike the original double implementation that stretches and collapses into horizontal bars, the fixed-point version sees a pixelated distortion instead:
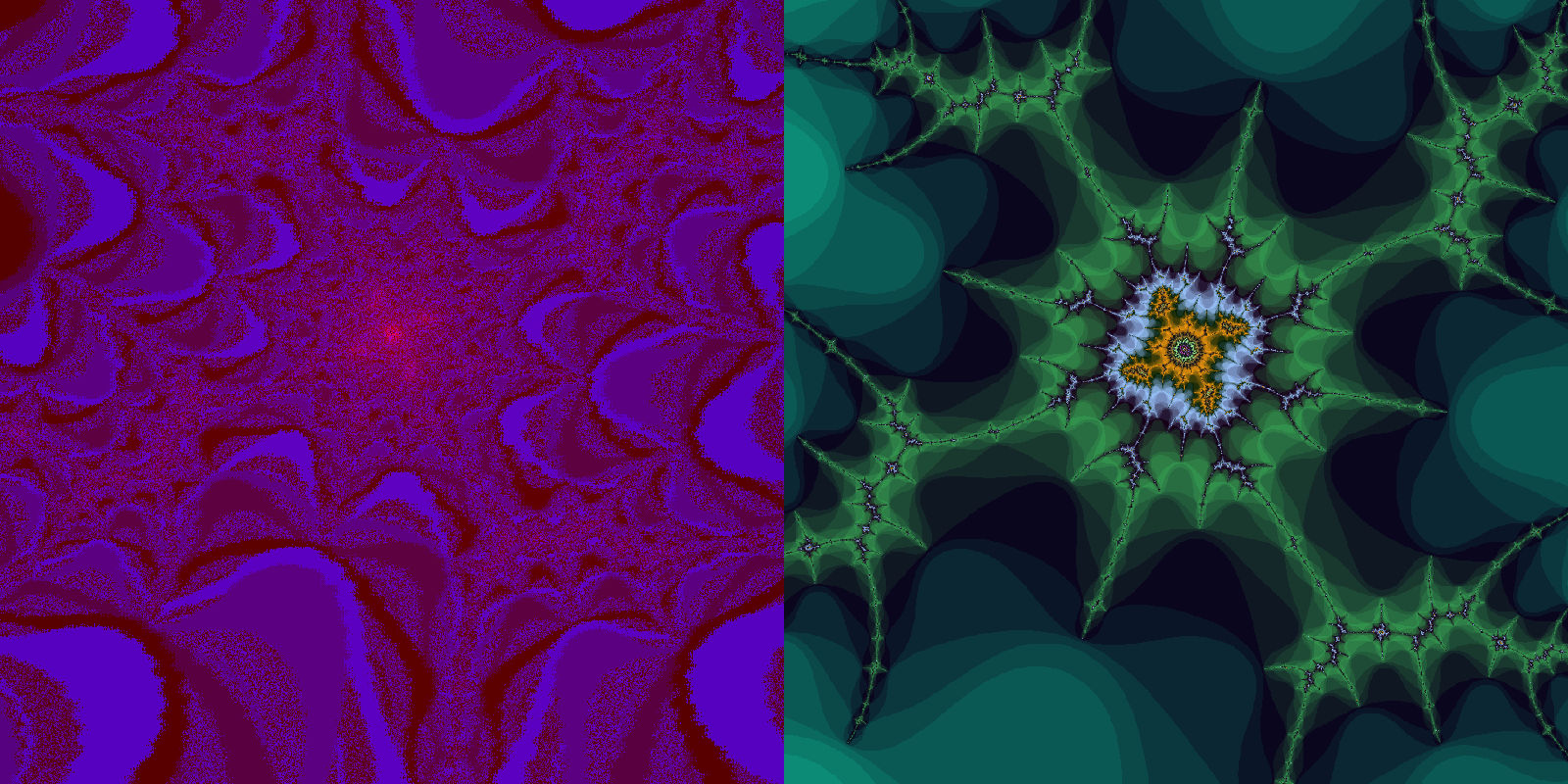
Pushing in further, the fixed-point image becomes very poor.
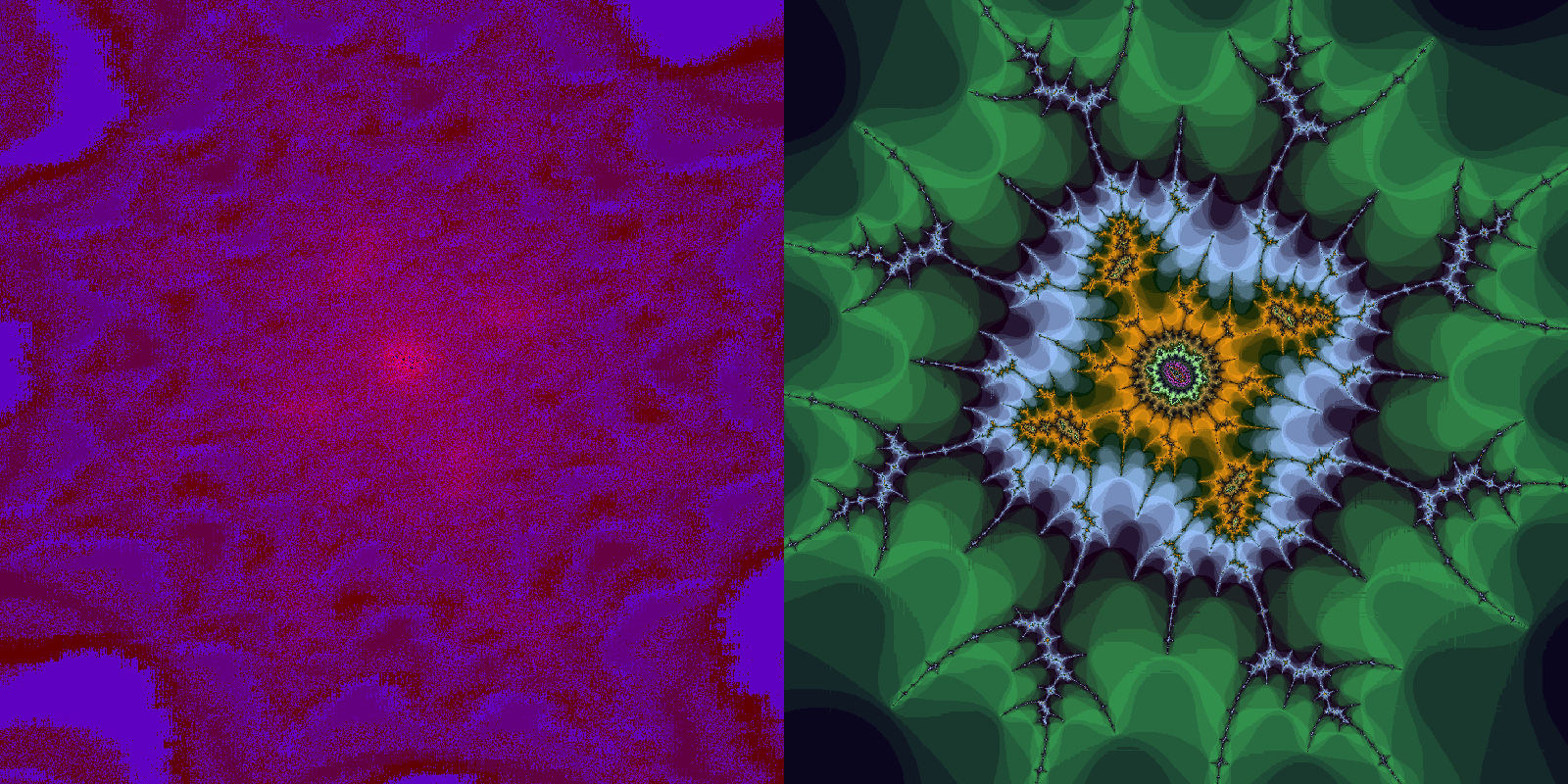
We actually find ourselves near the limits of XaoS though: zooming to the center of this design results in a similar distortion.

The secrets of XaoS
There are two secrets to the performance of XaoS, one of precision and another of speed. For precision, XaoS uses the 80-bit extended-precision format built into x86 processors. I chose to avoid this since it is not OpenCL compatible.
For my program, using OpenCL was a necessity for smooth framerates. double calculations could be done at 60+ FPS all the way to its limits; fixed-point calculations started around 50 FPS and slowly decreased with zooming. Keeping to the CPU resulted in a performance drop of at least 50%.
XaoS overcame its CPU-bound limitation by realizing a unique algorithm that predicts future pixels based on previous calculations. Reimplementing this strategy would be a whole new challenge on its own.
a benchmark
happy-fractal has compile-time switches for OpenCl and the fixed-point implementation. A third switch will do a "benchmark" that times a specific zoom sequence. This is how the four combinations run on my computer (Ryzen 1700X, 750 Ti):
floating-point, OpenCL: 4.95962s
floating-point, CPU: 10.30790s
fixed-point, OpenCL: 10.12300s
fixed-point, CPU: 34.11120s